If you have trouble viewing this, try the pdf of this post. You can download the code used to produce the figures in this post.
Detection with multinormal data
In my previous post, I showed that multivariate normal is a good model for x-ray measurements and in my last post I described the general properties of this distribution. In this post, I will discuss statistical detection theory with the normal model. I will show that the performance is characterized by a suitably defined signal to noise ratio. This will enable me to close the loop to the main topic of this series of posts, which is to explain the results in my paper, “Near optimal energy selective x-ray imaging system performance with simple detectors[1]”, which is available for free download here.
Section 3.3 of Kay[2] has an excellent discussion of classical statistical detection theory and Sec. 2.6 of Van Trees[4] describes its use with normal distributed data. I recommend that you study these references. Here, I will summarize and tie together their results. The main result will be that the probability of detection for a specified false alarm rate depends only on the signal to noise ratio (SNR) and the derivation of the SNR for vector data.
Binary decision making with mean-shifted data
Statistical detection theory is based on hypothesis testing. The simple binary hypothesis testing approach that I will use assumes that the probability distribution functions under both hypotheses are known. The problem is to decide between the hypotheses based on the random measurement(s). In my discussion, I will focus on the multinormal distribution with the same covariance under both hypotheses. With x-ray measurements, we know that the variance depends on the number of photons, which varies strongly with object thickness. This would seem to imply that the analysis is only applicable for thin features. In a future post, I will show that this is not necessarily true but the thin feature case is important since the objects significant for medical diagnosis like lung nodules or breast tumors are many times small. The equal covariance case is also widely used since it provides good insight to the factors affecting detection performance.
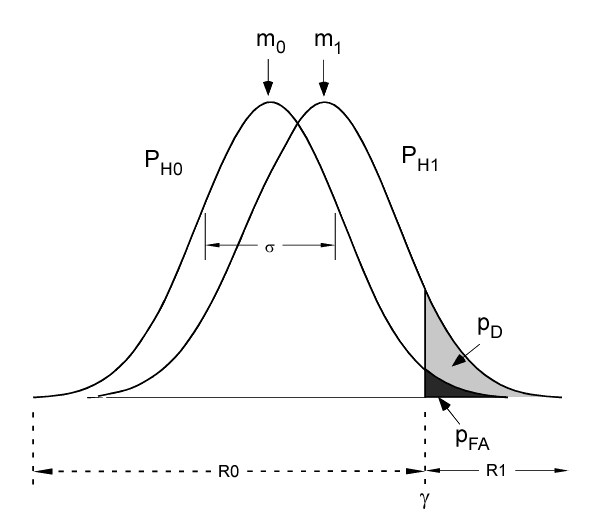
Suppose, we make just one measurement and the distributions PH0 and PH1 under the two hypotheses have the same variance σ with means m0 and m1 as shown in Fig. 1↓. To implement the detection algorithm, we divide the x-axis into two regions and decide H0 if the measurement is in R0 and H1 in R1. Because of the random data, we cannot eliminate errors. We can measure the performance by two parameters, the probability of detection, PD = Prob(H1;H1) and the probability of false alarm, PFA = Prob(H1;H0), where the notation Prob(Hi;Hj) means the probability of deciding Hi if Hj is true. Since m0 is less than m1 for the case shown in Fig. 1↓, a reasonable decision rule is to choose H0 if x is less than a threshold γ and H1 if it is larger. The equal case has zero probability so it can be assigned to either case. This leads to the decision regions R0 and R1 shown in the figure.
The Neyman-Pearson (NP) theorem
Given the data in Fig. 1↑, an immediate question is where to set the threshold. We cannot simultaneously minimize PFA and maximize PD but we can fix PFA at some pre-determined value α and maximize PD by using the Neyman-Pearson theorem
To maximize PD for a givenPFA = α, decide H1 if(1) R(x) = (p(x;H1))/(p(x;H0)) > τ
where the parameter τ is chosen soPFA = ⌠⌡{x;R(x) > τ}p(x;H0)dx = α
Note that the theorem is applicable to vector as well as scalar data.
Applying the NP theorem to scalar data
The probability distribution functions (PDF’s) under the two hypotheses are
Taking the logarithm of the likelihood ratio R in (1↑), substituting the PDF’s (2↑) and changing the variable to u = x − m0, the NP test is
ℒ(u) = logR = (u2 − (u − δm)2)/(2σ2) > logτ
Expanding the left side and rearranging terms, the NP test is u > γ’ where
With these, we can compute the optimal probability of detection for a specified false alarm rate. First, I will define some notation. Let F(x) be the cumulative distribution function of the N(0, 1) random variable
F(x) = (1)/(√(2π))x⌠⌡ − ∞e − (t2)/(2)dt
and Fc = 1 − F be its complement. Since u has an N(0, σ2) distribution
PFA = Fc⎛⎝(γ’)/(σ)⎞⎠
We can invert this since Fc is a monotonically decreasing function so γ’ = σF − 1c(PFA). Since p(x;H1) ~ N(δm, σ2), the probability of detection is
PD = Fc⎛⎝(γ’ − δm)/(σ)⎞⎠
Substituting for γ’,
This shows that the probability of detection for a given false alarm probability depends only on the signal to noise ratio (or its square)
(5) SNR2 = ((⟨x;H1⟩ − ⟨x;H0⟩)2)/(variance(x;H0))
where ⟨x;Hk⟩ denotes the expected value of x with the p(x;Hk) distribution.
We can evaluate Eq. 4↑ using Matlab functions to evaluate Fc, andF − 1c . The Matlab function normcdf computes F and Fc = 1 − normcdf. Also, the Matlab norminv function computes F − 1 and F(F − 1(x)) = x = 1 − Fc(F − 1(x)) so
Fc(F − 1(x))
=
1 − x
F − 1(x)
=
F − 1c(1 − x)
Setting t = 1 − x,
F − 1c(t) = norminv(1 − t)
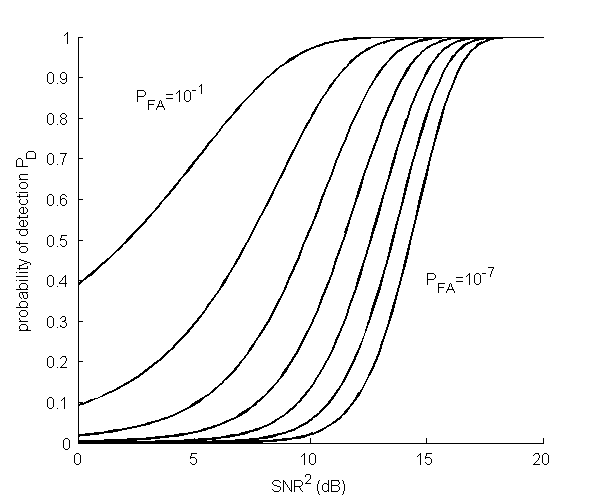
Fig. 2↓ shows the probability of detection PD as a function of the SNR2 in decibels (dB) for different values of the false alarm probability PFA. Note that as expected, PD always increases as the signal to noise ratio increases. The code to reproduce this figure is available here. This figure should be compared with Fig. 3.5 of Kay[2].
Binary decisions with vector data: the equal covariance case
With multivariate normal data and assuming equal covariance under the two hypotheses, the probability distributions are (see my last post).
p(x;Hk) = (1)/((2π)n⁄2| C|1⁄2)exp[ − 1⁄2( x − mk)TC − 1(x − mk)] k = 1, 2
where C is the covariance and n is the dimension of the vector data. Substituting in the definition of the likelihood ratio (1↑) and taking the logarithm of both sides, the log-likelihood is
ℒ(x) = − ((x − m1)TC − 1(x − m1) − (x − m0)TC − 1(x − m0))/(2)
Expanding the products, gathering terms, and defining δm = m1 − m0
− 2ℒ(x) = δmTC − 1x + mT1C − 1m1 − mT0C − 1m0
The last two terms on the right hand side do not depend on the data and a multiplicative factor does not not affect the results so the Neyman-Pearson test is
The log-likelihood ℒ(x) is a linear combination of a multivariate normal random variable so it also has normal distribution. It is a scalar so we can apply the results of the previous section to see that the performance is determined by the SNR2 from Eq. 5↑
(7) SNR2 = ((⟨ℒ;H1⟩ − ⟨ℒ;H0⟩)2)/(variance(ℒ;H0))
Using the definition of variance
From the definition of ℒ (6↑) and the expected value (8↑),
ℒ(x) − ⟨ℒ;H0⟩
=
δmTC − 1(x − m0)
=
(x − m0)TC − 1δm
where the last step follows because ℒ is a scalar so it is equal to its transpose as is the covariance because it is symmetric.
(11)
variance(ℒ;H0)
=
⟨ δmTC − 1(x − m0)(x − m0)TC − 1δm⟩
=
δmTC − 1CC − 1δm
=
δmTC − 1δm
Substituting (9↑) and (11↑) in (7↑), the vector SNR2 is
(12) SNR2 = δmTC − 1δm
Example: “white” data
Data with independent, equal variance provide good insight and are also important in practice since we can use the whitening matrix, Φw discussed in my last post, to transform any multinormal to this case. In a future post, I will describe how we can use whitening with x-ray spectral data.
For whitened data, the covariance matrix is C = σ2 I and its inverse is C − 1 = 1⁄σ2 I. Substituting in (12↑), the signal to noise ratio is
SNR2W = (|δm|2)/(σ2)
This is the distance between the means squared divided by the variance. From (6↑), the NP test is
ℒ(x) = (1)/(σ2) δmTx > γ’
This is the dot product of the data with the mean difference vector δm.
Conclusion
I have now provided the statistical detection theory framework that I will use to analyze the Tapiovaara-Wagner imaging task[3] for x-ray data with spectral information. We can use this framework to introduce the basis set expansion of the attenuation coefficient as shown in my paper[1]. This will allow us to compare the performance of systems with limited energy resolution to the ideal case with full spectral information.
Bob Alvarez
Last edited Jan 20, 2012
© 2012 by Aprend Technology and Robert E. Alvarez
Linking is allowed but reposting or mirroring is expressly forbidden.
References
[1] : “Near optimal energy selective x-ray imaging system performance with simple detectors”, Med. Phys., pp. 822—841, 2010.
[2] : Fundamentals of Statistical Signal Processing, Volume 2: Detection Theory. Prentice Hall PTR, 1998.
[3] : “SNR and DQE analysis of broad spectrum X-ray imaging”, Phys. Med. Biol., pp. 519—529, 1985.
[4] : Detection, Estimation, and Modulation Theory. Part I: Detection, Estimation, and Linear Modulation Theory. John Wiley & Sons Inc, 2001.